들어가기기 앞서...
이전 포스팅에서 말씀드린대로 Scale out을 프로젝트에 반영하기로 하였습니다.
혹시라도 왜 Scale up이 아닌 Scale out을 선택하였는지 궁금하신 분들이 있으시다면 이전 포스팅을 참고 부탁드립니다.
Scale out을 반영한다고 했는데 너무 막연했습니다.
뭘 어떻게 해야하지?? 일단 사용자의 요청부터 의식의 흐름대로 생각해 보도록 하였습니다.
대규모 트래픽을 감당하기위해 서버를 여러 대 두었고..
그러면 사용자들이 로그인을 하고 A서버에 접근해서 데이터를 가져오고 그 다음 요청할때 A가 아닌 B서버에서 데이터를 가져오고.. 🤔....? 데이터를 가져올 수 있나?
A서버로 로그인 요청을 처리해서 B 서버는 세션정보가 없는데..? 그럼 로그인 요청을 처리한 A서버 한테만 요청을 해야하나? 그건 또 누가하지...? 아니 잠깐만.. 애초에 사용자들이 A, B 서버를 선택하여 요청을 보낼 수가 있나..?
이런 생각들이 꼬리에 꼬리를 물어 머리를 복잡하게 만들었습니다. 😭
그래서 구글링을 통해 다양한 세션처리에 대해 알 수 있었습니다. 그래서 이번 포스팅은 구글링을 통해 알게된 내용들을 정리하는 글이 될 것 같습니다.
우선 세션을 처리방법에는 크게 3가지가 있습니다.
- Sticky Session
- Session Clustering
- Session Storage
그럼 각각에 대해서 한번 정리해보겠습니다~!
Sticky Session

Sticky는 '끈적거리는', '달라붙는' 이란 뜻을 가지고 있습니다. 즉 클라이언트 요청을 처음 수신한 server에게 달라붙어, 이후 해당 클라이언트의 모든 요청은 처음 수신한 서버가 처리하는 기술입니다. 해당 기술을 Load Balancer 기능을 담당하는 L4, L7 장비에게 옵션으로 설정 할 수 있습니다.
처리순서
- Client 요청이 들어오면 Load Balancer를 통해 WAS에 전달됩니다.
- WAS는 Client가 요청한 Http 헤더 정보 중 Set-Cookie 정보를 확인하여 SessionID값이 없으면 발급하여 Set-Cookie의 값으로 넣어서 송신합니다.
- 송신된 데이터는 당연히 Load Balancer가 수신하며, 이때 Load Balancer는 WAS 응답 중 Set-Cookie에 SessionID가 있는지 검사합니다. 만약 있다면 내부적으로 쿠키와 서버ID를 맵핑시켜 로드밸런싱이 되도록 합니다.(Cookie 스위칭 기준)
- 그런다음 Load Balancer는 Client에게 WAS에게 전달받은 정보를 전달합니다.
- SessionID값을 수신한 Client는 이후 모든 Http 요청할때 헤더에 SessionID를 포함하여 전달합니다.
- 이를 Load Balancer가 확인하여 WAS에게 전달하게 됩니다.
Load Balancer는 그러면 이후 Client의 쿠키에 등록된 값을 확인하여 Sticky Session처리를 하는 건 알겠는데 만약 쿠키에 SessionID값이 없을경우엔 어떤 방식으로 처리할까요? 없는 경우에는 Load Balancer에 설정한 알고리즘(Round Robin, Least Connections 등)을 통해서 동작하게 됩니다. 이 부분은 해당 포스트의 내용에 벗어나는 부분인것 같아 추후 NginX를 사용할때 정리하도록 하겠습니다.
장점
- 별도의 세션 서버를 두어 처리할 필요가 없어 인프라 구성이 간단해집니다.
- 별도의 세션 서버를 두지 않으므로 세션데이터 교환에 따른 비용이 들지 않습니다.
단점
- 특정 WAS에 트래픽이 몰리거나, 특정 WAS에 트래픽이 상대적으로 현저하게 적을수도 있습니다.
- 서비스 도중 WAS가 장애상황이 발생하면 Load Balancer의 정책에따라 Failover(시스템대체작동)를 하게됩니다. 이로인해 대체된 WAS에는 해당 세션정보가 없어 로그인 등을 요구할 수 있습니다.
Sticky Session의 단점으로 트래픽이 왜 몰리나요??
이 질문에 대한 답은 L4, L7 로드밸런서에 힌트가 있습니다.
여기서 말하는 L4, L7는 OSI 7계층의 전송계층, 응용계층을 말합니다.
이후 내용이해를 위해 간단하게 정리하자면 L4 전송계층(Transport layer)은 Load balancing을 IP, Port를 사용하여 처리합니다.
L7 응용계층(Application layer)는 IP, Port, 프로토콜 헤더를 통해 Load balancing을 하게됩니다.
일단 네이버에 '내 아이피' 라고 검색을 해보겠습니다. 그럼 공인 아이피가 나오게 됩니다.
그럼 와이파이에 연결되어있는 휴대폰에도 똑같이 검색을 해보겠습니다. 뭔가.. 이상하지않은가요?
분명 이기종인데 동일한 공인 아이피가 출력되었습니다. 즉 해당 건물에서 나가는 공인IP는 정해져 있습니다.
이 말은 L4로드밸런서로 Sticky Session을 사용하면 ip, port만 확인가능함으로 해당 로드밸런서는 해당 건물에서 수 많은 기기들의 요청을 동일인으로 판단하고 이를 동일 서버에만 전송하게됩니다.
이러한 문제로 인해 트래픽이 하나의 서버로 몰릴 수 있습니다.
그래서 이러한 단점을 해결하기위해 L7 로드밸런서를 사용하여 처리하면 해당 문제를 해결할 수 있습니다. 이유는 L7 는 OSI 7 계층 중 응용계층에 해당하며 해당 계층은 프로토콜 헤더를 조작할 수 있기 때문입니다. 그래서 http헤더에 Set-Cookie 값을 확인하여 서버와 맵핑시킬 수 있기 때문에 라운드로빈 등의 알고리즘을 통해 L4 로드밸런서에서 발생한 문제점을 해결할 수 있습니다.
그러면 Sticky Session으로 결정?!
처음엔 L7 로드밸런서를 사용하면 트래픽이 한 곳에 집중되는 현상을 해결할 수 있으니, 이걸 적용하자 생각했습니다. 하지만 생각해보니 맹점이 있었습니다. 바로 단점에서 말씀드린 2번째 문제로 인해 사용자들은 장애발생 시 불필요한 로그인을 한번 더 할 필요가 생겼습니다.
해당 문제를 고민하다가 답이 나오지 않아 다시 처음으로 돌아가 해당 문제를 바라보니 의외의 곳에서 실마리를 잡을 수 있었습니다. 현재 제가 진행하고 있는 프로젝트는 SNS 서비스임으로 서버 장애가 발생하여도 사용자들은 이를 모르고 별 탈 없이 사용하여야 하며, SNS는 서비스 시간이 돈이라는 부분을 다시 상기 시켰습니다.
즉 서버에 장애가 발생하여 사용자들이 재 로그인을 하게된다면 많은 사용자들이 불편함을 느낄것이고 이는 곳 서비스 사용에 지장이 생길 것이라 판단하였습니다.
Tomcat Session Clustering
Sticky Session의 단점을 보완하기위해 세션 클러스터링 이란 개념이 있습니다.
클러스터링이란 똑같은 구성을 가진 서버들이 병렬로 연결되어 하나의 서버처럼 동작하는 것을 말합니다. 즉 세션 클러스터링이란 각각의 WAS가 가지고있는 세션들을 서로 연결하여 마치 하나의 세션서버가 있는 것 처럼 동작하도록 하는 기술입니다.
WAS는 Tomcat, Netty 등 여러종류가 있지만 여기서는 제 프로젝트에서 사용하고있는 Tomcat 9를 기준으로 설명드리도록 하겠습니다.
Tomcat 9는 Near-memory, In-memory방식으로 나뉘어 볼 수 있습니다.
Near-memory
PersistentManager를 사용하여 FileStore를 하거나, JDBC 드라이버를 통해 연결된 DB로 세션을 처리할 수 있습니다.
In-memory
DeltaManager방식
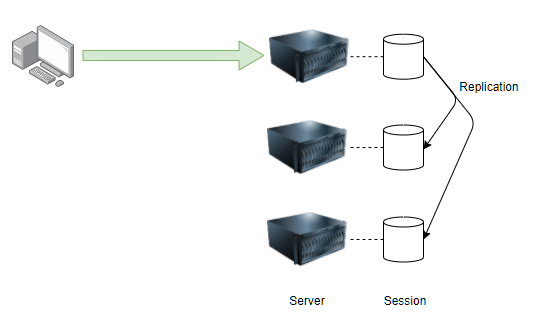
모든 WAS의 세션들이 replication되도록 설정합니다. 이를 All-to-All replication방식이라고 표현합니다.
이 방식은 WAS의 갯수가 증가함에 따라 모든 세션들이 replication하기때문에 네트워크 트래픽이 증가하게되며, In-memory방식이므로 메모리 사용량이 증가한다는 단점이 있습니다.
하지만 가장 확실한 세션 클러스터링이라 할 수 있습니다. 그래서 WAS가 4개 정도라면 DeltaManager를 사용한 All-to-All replication방식을 사용하는 것도 하나의 방안이 될 수 있다고 합니다.
BackupManager방식
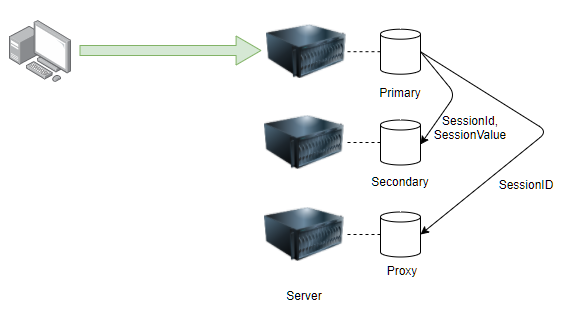
DeltaManager의 문제점을 보완하여 나온 개념으로 primary-secondary방식입니다. 세션정보는 내부적으로 key-value방식으로 SessionId-SessionValue로 저장되어있습니다.
처리방식
WAS가 3개 있다고 가정합니다. (이하 A,B,C)
- 사용자 요청이 들어오면 이를 수신한 A가 Session을 생성하고 Primary가 됩니다.
- A가 B ~ C에게 Heartbeat를 전송하여 가장먼저 응답이 온 WAS를 Secondary로 지정합니다. (글의 흐름을 돕기위해 여기서는 B가 Secondary)
- A는 B에게 세션정보(SessionId, SessionValue)를 전달합니다.
- Secondary가 되지못한 WAS는 Proxy가 되어 A가 전달한 SessionId만 수신받게 됩니다.
- 만약 proxy에 요청이 들어오면 해당 WAS는 SessionID를 primary에게 요청하여 처리하게됩니다.
DeltaManager를 사용하는 것 보다는 아무래도 세션정보를 전부 전달하는 것이 아님으로 데이터 전송량이 상대적으로 적을 것으로 판단됩니다. 또한 수신된 세션정보가 작다보니 메모리 사용량도 덩달아 감소하게됩니다.
하지만 BackupManager도 DeltaManager에 비해서 네트워크 트래픽 및 메모리 사용량이 감소되는 것이지 WAS의 갯수가 증가함에 따라 비례하게 트래픽, 메모리가 증가하게 될 것입니다.
Tomcat Session Clustering 적용 가능한가?!
결론적으로 서버의 갯수가 많아짐에 따라 서버단 자체적인 트래픽 증가와 메모리 증가는 결국 서버들이 감당해야될 리소스가 더 많아진다는 것을 뜻합니다.
WAS의 갯수들이 적을때는 그나마 고려해볼 수 있겠지만 대용량 트래픽을 고려하여 설계한 부분인 만큼 세션 클러스터링은 적용하기 힘들겠다고 판단하였습니다.
Session Storage
세션이 불일치 되는 현상의 가장 근본적인 원인은 각각의 WAS가 세션을 처리하고 관리하기 때문입니다.
즉 세션을 여러대의 WAS가 각각 처리하는 것이 아니라 한곳에서 관리하고 처리한다면 세션 불일치 현상은 해소될 것 입니다. 이러한 개념이 바로 Session Storage입니다.
모든지 완벽한 기술을 없습니다. Session Storage를 사용한다고 해서 문제점이 없는것은 아닙니다. Session Storage로 삼았던 저장소도 장애상황이 발생할 수 있으므로 이중화를 구성하는 등 복구 및 복원 전략을 잘 세워야 합니다.
장점
- 세션 데이터를 한 곳 에서 관리 하기 때문에 세션 불일치 문제가 발생할 일이 없습니다.
단점
- 세션에 대한 모든 요청 및 처리는 Session Storage에 요청해야 함으로 요청마다 Network I/O가 발생합니다.
- 세션을 한 곳에서 관리하기 때문에 만약 저장소에 장애가 발생 하게되면 별도의 이중화 구성 등이 필요합니다.
결론
Sticky Session, Session Clustering, Session Storage 구성 및 각각의 장단점을 살펴보았습니다.
각각의 기술별로 장단점이 있었지만 현재 진행하고 있는 프로젝트에 얼마나 적합한지를 생각해 보았고, Session Storage를 사용하는 것으로 결정하였습니다.
Session Storage를 사용하기위해선 일단 알맞는 스토리지를 선정해야합니다.
다음 포스팅에서는 세션을 처리하기위해 가장 적합한 스토리지를 찾는 과정을 작성해 보도록 하겠습니다.
생각보다 글이 길어졌네요..😫 긴 글 읽어주셔서 감사합니다.
참고자료
https://aws.amazon.com/ko/blogs/aws/new-elastic-load-balancing-feature-sticky-sessions/
https://tomcat.apache.org/tomcat-9.0-doc/cluster-howto.html
https://www.freeism.co.kr/wp/archives/698
'프로젝트 > Careers' 카테고리의 다른 글
| CI/CD 왜 필요한가? (0) | 2021.08.05 |
|---|---|
| Session Storage 선택과정 (0) | 2021.07.29 |
| Jenkins를 통한 CI/CD 도입 (0) | 2021.07.07 |
| Java CheckStyle 적용 (0) | 2021.06.10 |
| 대규모 트래픽을 고려한 서버 확장 방법 (0) | 2021.04.06 |


댓글